Paper Review Process
For the review process at NAACL-HLT 2021, we largely adopted the best practices of other recent virtual conferences, while modifying the format somewhat to treat all papers equally, as described in more detail below. Our paper review process followed the recent trend of a hierarchical organization, with senior area chairs (SACs) that organized coherent research tracks and area chairs (ACs) who shepherded smaller batches of papers within each track.
NAACL-HLT 2021 received 1797 submissions–a record for our conference! We accepted 477 papers, including 350 long and 127 short, for an overall acceptance rate of 26%. The acceptance rate for long papers was higher than short papers (28% vs. 23%), although this gap was smaller than in other recent conferences at least in part due to minor but explicit rebalancing done the the PC chairs. The following graphs show how these numbers break down in comparison to previous years.
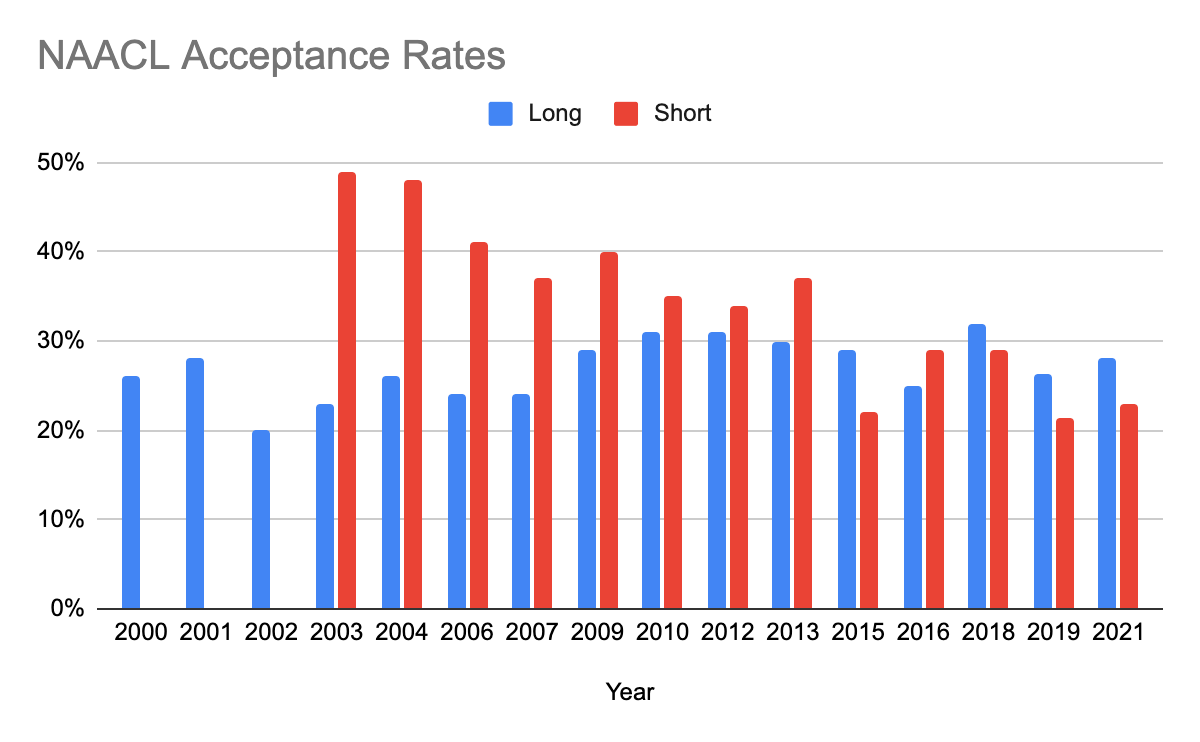
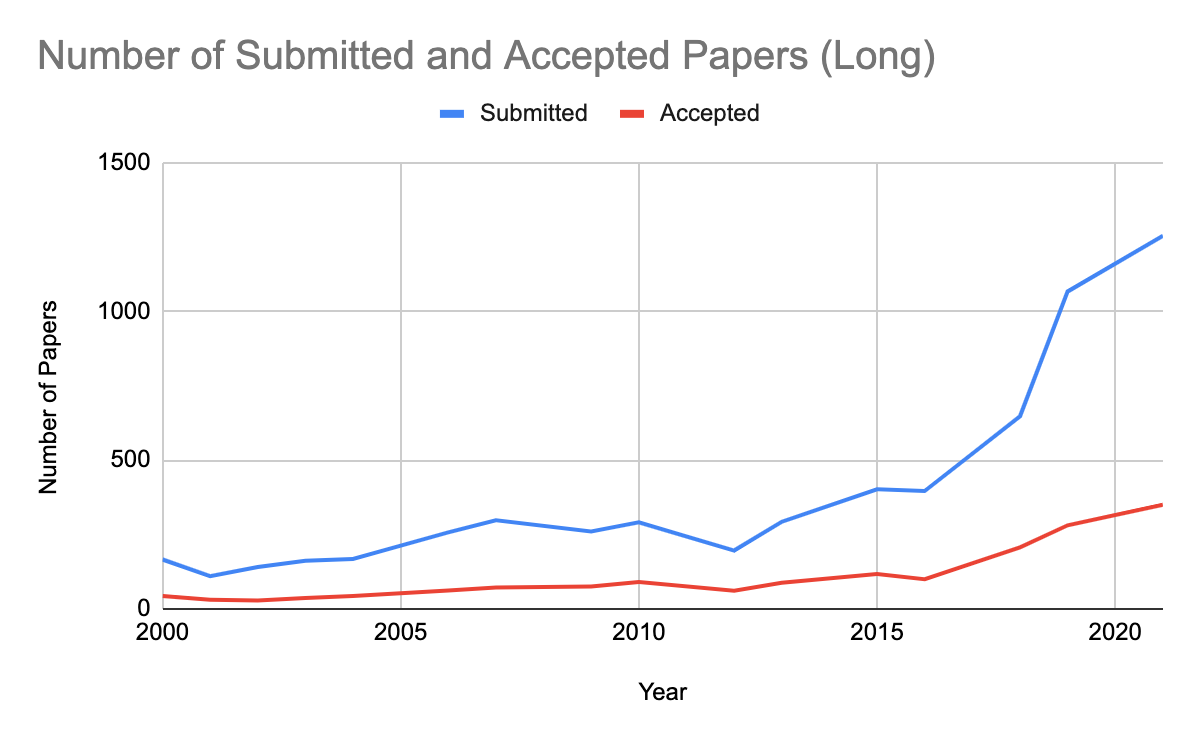
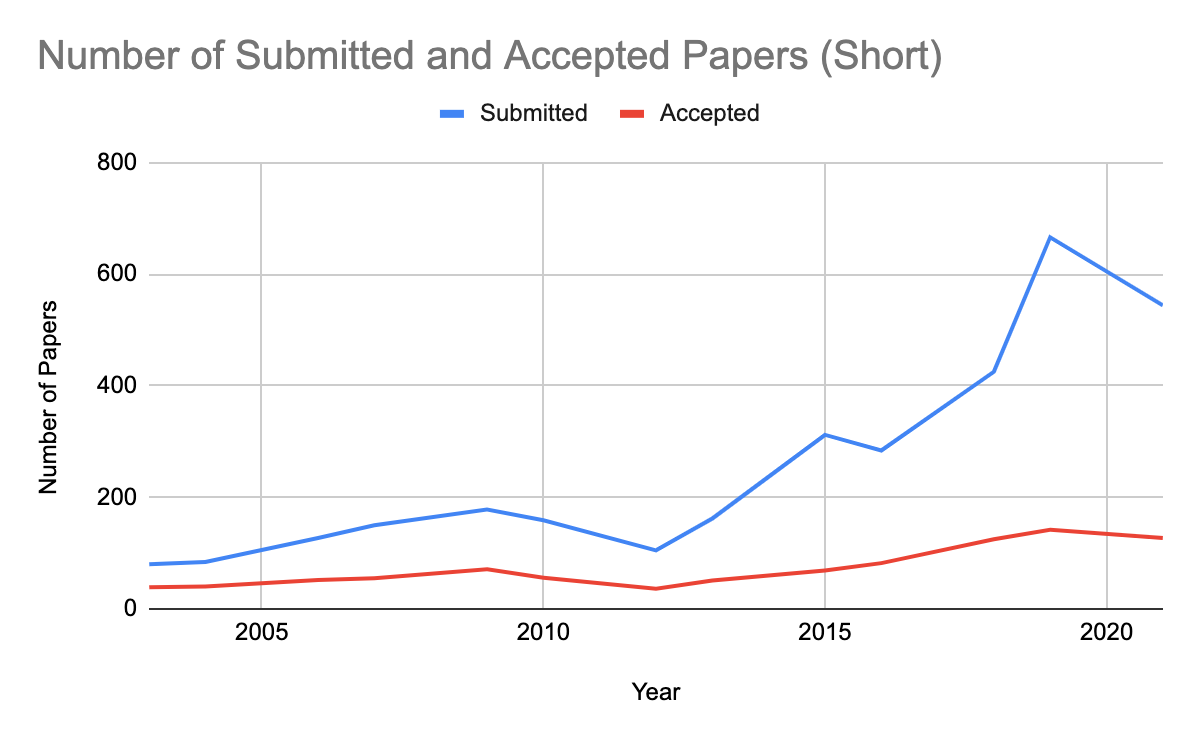
From the accepted papers, and based on the nominations from SACs and review by the best paper committee, we selected the best papers in the long and short paper categories, as well as a small number of outstanding papers in each category. The best paper selection process is described here. NAACL-HLT 2021 will also feature 18 papers that were published at Transactions of the Association for Computational Linguistics(TACL) and 4 papers from the journal of Computational Linguistics(CL).
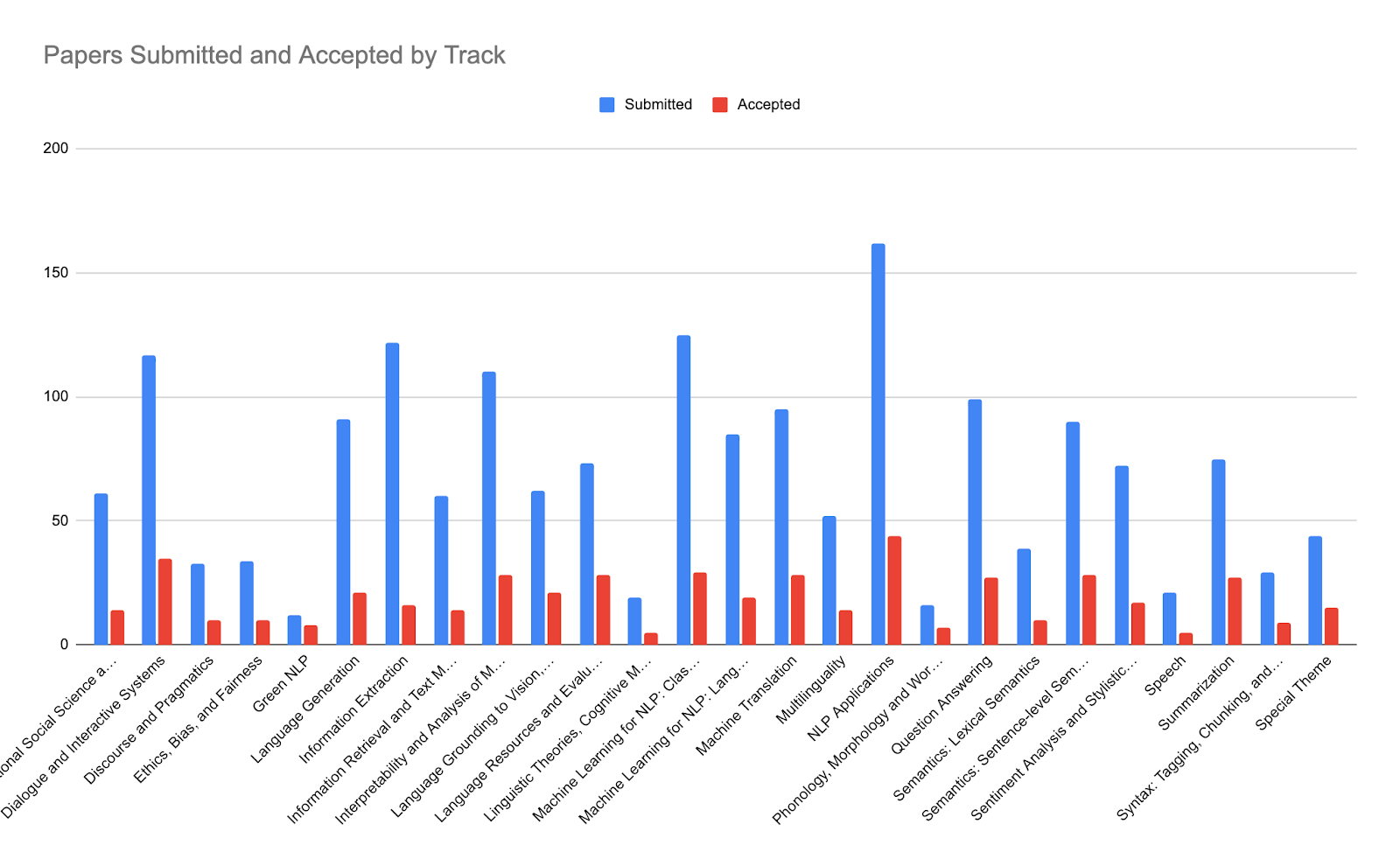
When designing the call for papers, we made an effort to balance the size of the tracks. Recent NLP conferences have had many tracks that received well over 200 submissions, making them mini-conferences of their own. To make the senior area chairs’ jobs more manageable, we split the machine learning track by areas (into “Classification and Structured Prediction Models” and “Language Modeling and Sequence to Sequence Models”) and separated Machine Translation from Multilingual. We also wrote a brief guide to authors, including descriptions of areas, to help them decide which track was most appropriate for their work. Overall, we felt that this did make the organization more manageable and that other tracks, including NLP applications, could possibly benefit from further splitting in future conferences. Otherwise, we followed recent traditions in track selection, including keeping some of the smaller, more recent additions (e.g. Green NLP and Ethics). The following graph shows a list of the paper submission and acceptance numbers per track.
We also had a special theme for the conference, which we called “New Challenges in NLP: Tasks, Methods, Positions.” This theme was selected to recognize that we have made significant progress in NLP over the last five years, and that the community could benefit from thinking about the new problems and upcoming challenges we should focus on next. Despite the general applicability of the unsupervised pre-training/fine-tuning paradigm, many problems are still very challenging for current models. At the same time, given the recent progress, there are likely broad new classes of problems that can now be studied for the first time. Hence, the special theme targeted papers focusing on: “What tasks or capabilities should we focus on next?” and “What new classes of models should we be investigating?” We envisioned papers falling into this theme including (but not limited to) (1) empirical and dataset papers that propose new challenges that bring us closer to human-level language understanding and generation, and (2) position papers framing an important direction or highlighting an understudied research problem.
We recruited reviewers through a centralized process, designed to minimize workload for senior area chairs (SACs) without sacrificing review quality. We collected a list of likely qualified reviewers based on the reviewer and author pool of other recent NLP conferences. These candidates were invited to sign up to review, and were required to fill out a profile that allowed us to better assess their potential area fit and experience levels. We were fortunate enough to have enough volunteers to not need everyone, and were able to bias the final selection towards more senior reviewers, although many junior and first time reviewers remained in the pool. The final program committee included 54 SACs, 267 ACs, and 1941 committee members. We greatly appreciate the incredible amount of work they all did, and also thank all of the volunteers who were not selected in the end.
There was one part of the review process that we did this year, which we would likely not repeat in hindsight. We coordinated the review process so that authors could see their reviews and withdraw their paper to resubmit to ACL 2021 if they were not happy with the quality. Hundreds of papers were withdrawn, and anecdotal evidence suggests that many of them would have been accepted if they had been left in the pool. We hope that initiatives like the ACL Rolling Review will provide more robust solutions to these types of problems in the future, and otherwise suspect overlapping review periods will just become the norm as conferences continue to grow.
Finally, for reference, here is a full table with all the per-track paper acceptance statistics.
| Area\Number of | Long Paper Submissions | Long Papers Accepted | Short Paper Submissions | Short Papers Accepted | All Papers Submissions | All Papers Accepted |
|---|---|---|---|---|---|---|
| Computational Social Science and Social Media | 44 | 11 | 17 | 3 | 61 | 14 |
| Dialogue and Interactive Systems | 90 | 30 | 27 | 5 | 117 | 35 |
| Discourse and Pragmatics | 19 | 7 | 14 | 3 | 33 | 10 |
| Ethics, Bias, and Fairness | 15 | 4 | 19 | 6 | 34 | 10 |
| Green NLP | 8 | 5 | 4 | 3 | 12 | 8 |
| Language Generation | 73 | 20 | 18 | 1 | 91 | 21 |
| Information Extraction | 95 | 15 | 27 | 1 | 122 | 16 |
| Information Retrieval and Text Mining | 38 | 7 | 22 | 7 | 60 | 14 |
| Interpretability and Analysis of Models for NLP | 70 | 16 | 40 | 12 | 110 | 28 |
| Language Grounding to Vision, Robotics and Beyond | 45 | 13 | 17 | 8 | 62 | 21 |
| Language Resources and Evaluation | 53 | 26 | 20 | 2 | 73 | 28 |
| Linguistic Theories, Cognitive Modeling and Psycholinguistics | 13 | 3 | 6 | 2 | 19 | 5 |
| Machine Learning for NLP: Classification and Structured Prediction Models | 84 | 21 | 41 | 8 | 125 | 29 |
| Machine Learning for NLP: Language Modeling and Sequence to Sequence Models | 58 | 11 | 27 | 8 | 85 | 19 |
| Machine Translation | 60 | 19 | 35 | 9 | 95 | 28 |
| Multilinguality | 34 | 10 | 18 | 4 | 52 | 14 |
| NLP Applications | 109 | 35 | 53 | 9 | 162 | 44 |
| Phonology, Morphology and Word Segmentation | 10 | 5 | 6 | 2 | 16 | 7 |
| Question Answering | 68 | 20 | 31 | 7 | 99 | 27 |
| Semantics: Lexical Semantics | 29 | 9 | 10 | 1 | 39 | 10 |
| Semantics: Sentence-level Semantics and Textual Inference | 66 | 20 | 24 | 8 | 90 | 28 |
| Sentiment Analysis and Stylistic Analysis | 56 | 15 | 16 | 2 | 72 | 17 |
| Speech | 10 | 3 | 11 | 2 | 21 | 5 |
| Summarization | 53 | 22 | 22 | 5 | 75 | 27 |
| Syntax: Tagging, Chunking, and Parsing | 20 | 7 | 9 | 2 | 29 | 9 |
| Special Theme | 34 | 12 | 10 | 3 | 44 | 15 |
| Total | 1254 | 366 | 544 | 123 | 1798 | 489 |